1CUHK-Shenzhen
2Sun Yat-sen University
3Shanghai Jiao Tong University
4USTC 5The University of Hong Kong
6University of Oxford
7Harvard University
*Equal contribution †Corresponding author
Recent advancements in foundational models have greatly enhanced the capabilities of robotics, yet acquiring large-scale, high-quality training data remains a challenge due to extensive manual effort and limited coverage of real-world environments. We propose Compositional Simulation, a hybrid approach combining classical simulation and neural simulation to generate accurate action–video pairs while maintaining real-world consistency. Our method utilizes a closed-loop real–sim–real data augmentation pipeline, leveraging a small amount of real-world data to produce diverse, large-scale training datasets. A neural simulator transforms classical simulation videos into realistic representations, improving the accuracy of policy models trained for real-world deployment. Experiments demonstrate that our method significantly reduces the sim2real domain gap, resulting in higher success rates in real-world policy training and offering a scalable solution for bridging simulation and reality in robotics.
With the rapid advancements in foundation models—from large language models to video generation world models—robotics has entered an era where data-driven paradigms can enable increasingly autonomous and generalizable behaviors. Yet a fundamental bottleneck remains: how do we obtain sufficient high-quality training data for robot policies?
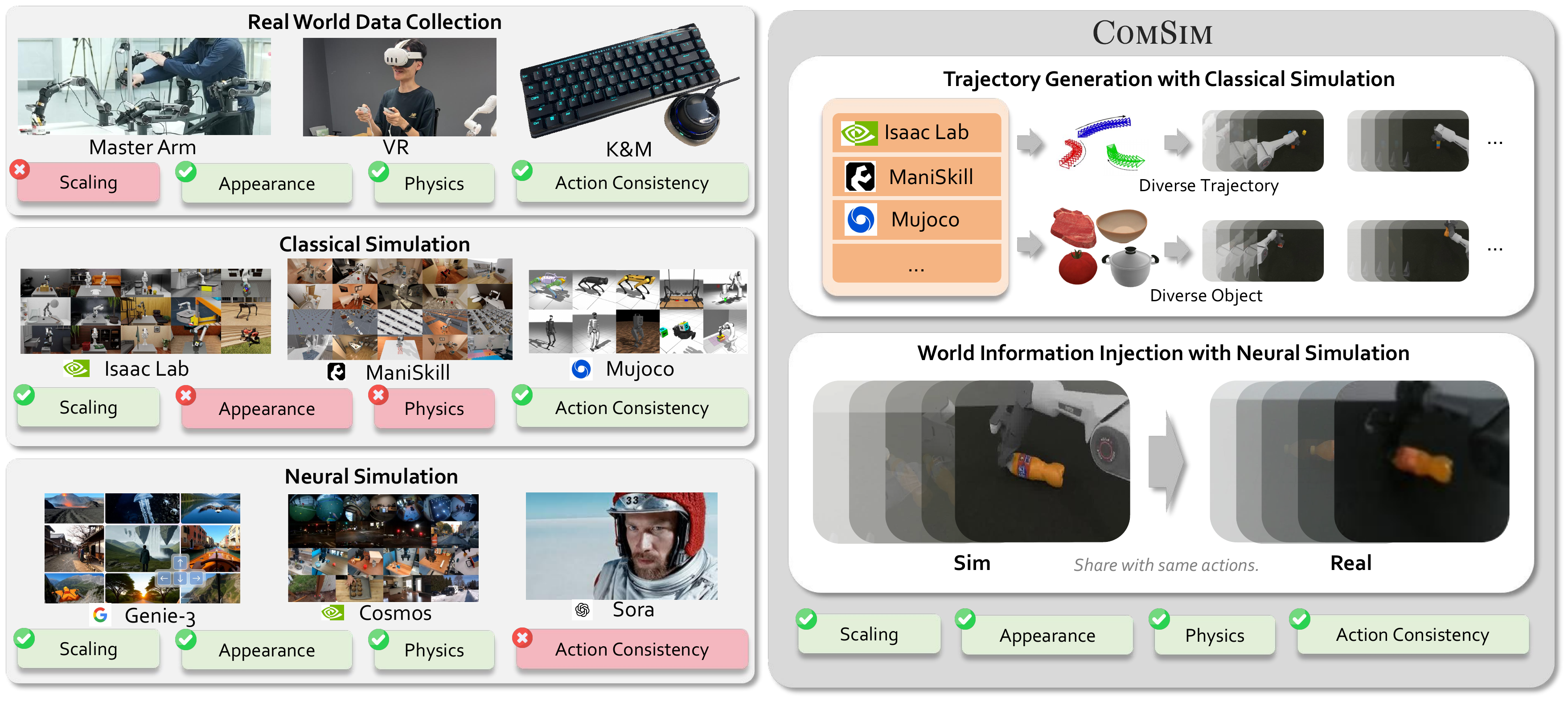
Collecting real-world demonstrations yields high-quality samples but is expensive and poorly scalable. Classical simulators (e.g., MuJoCo, Isaac Gym, SAPIEN) generate massive action-video pairs cheaply and at scale, but suffer from appearance and physics gaps that derail direct sim-to-real transfer. Neural simulators based on video generation can narrow visual gaps, but hallucinations and weak action consistency undermine their usefulness for policy training.
In this work, we advocate for Compositional Simulation—a hybrid paradigm that composes the precise action control of classical simulators with the photorealism of neural simulators. Through a closed-loop real–sim–real pipeline, as little as 10 real-world demonstrations suffice to bootstrap the generation of large-scale, photorealistic training data, substantially boosting real-world policy success and generalization.
Motivation of Compositional Simulation. There are three main sources of real-world robotic data: (1) direct human collection, which yields high-quality samples but cannot scale; (2) classical simulators, which generate large datasets but suffer from appearance and physics gaps to reality; and (3) neural simulators trained on real data, which reduce these gaps but struggle with action-conditioned video generation. Our Compositional Simulation bridges classical and neural simulation via compositional dynamic video generation.
Method
Compositional Simulation operates through a closed-loop real–sim–real pipeline that transforms a small amount of real-world data into large-scale, photorealistic training data for robot policies:
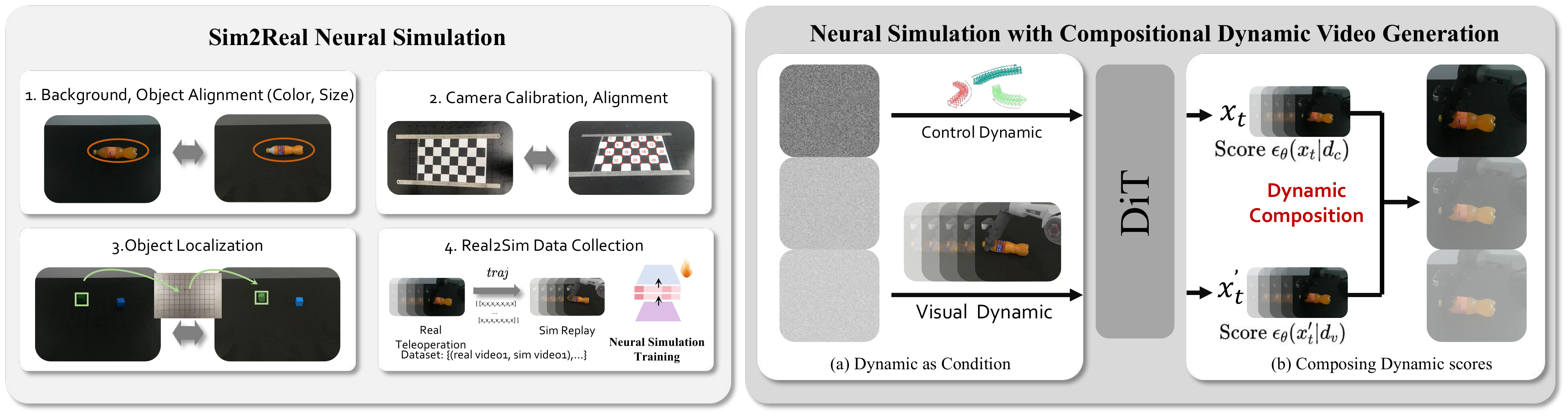
Real2Sim Alignment & Paired Data Collection: We strictly align the classical simulator with the real-world platform along three dimensions—background and object appearance, camera intrinsics/extrinsics, and object positions. Real-world trajectories are then replayed in simulation to form ($\mathcal{V}_{\text{sim}}$, $\mathcal{V}_{\text{real}}$, $\mathcal{A}$) tuples that share the same action sequence.
Compositional Dynamic Video Generation: A DiT-based neural simulator is trained to translate simulation videos into real-world video representations. It estimates scores conditioned jointly on Control Dynamics (actions) and Visual Dynamics (simulated observations), which are composed during sampling through Dynamic Guidance to ensure both photorealism and action consistency.
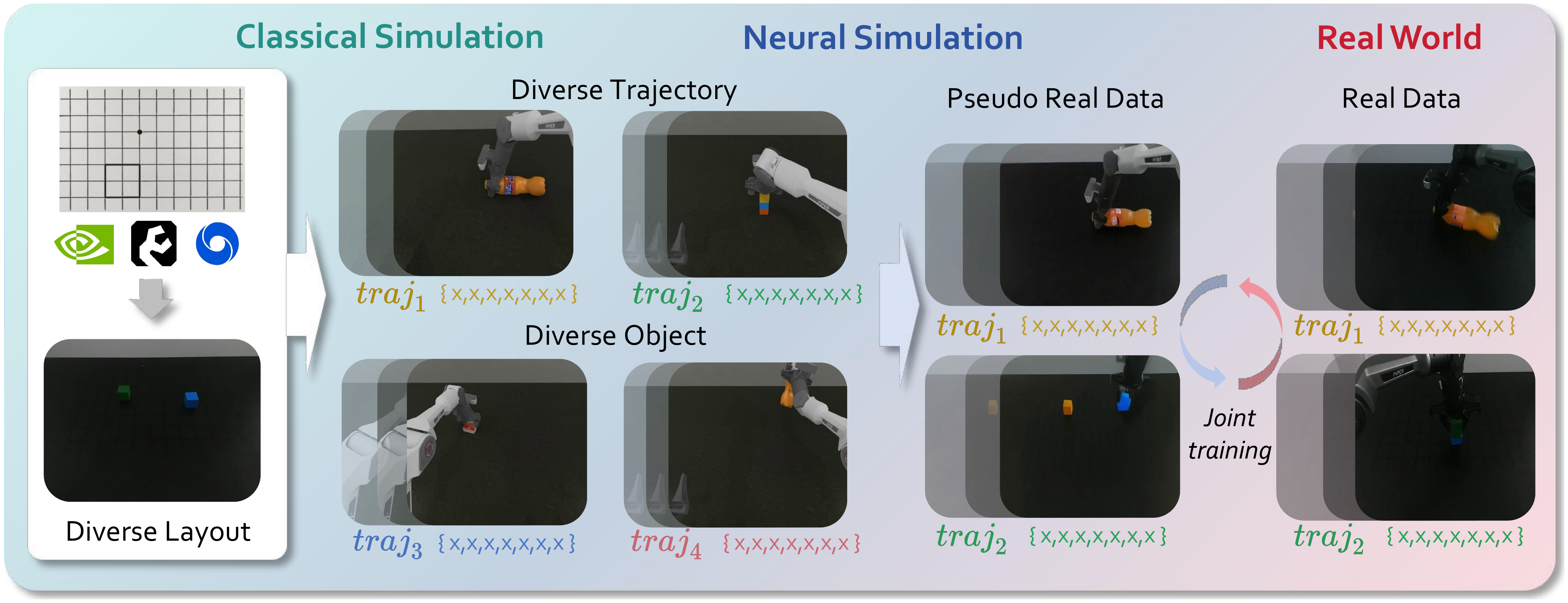
Rule-Based Large-Scale Data Synthesis: In RoboTwin we synthesize diverse trajectories via GPT-5-driven compositions of action primitives under semantic and physical constraints. The classical simulator produces clean ($\mathcal{V}_{\text{sim}}$, $\mathcal{A}$) pairs that span broad spatial and object variations.
Real-World Policy Deployment: Every simulated video is passed through the trained neural simulator, producing Pseudo-Real data that retains the original actions but looks real. Combined with a handful of real demonstrations, these data train robot policies (Diffusion Policy) that achieve high success rates and strong spatial/object generalization.
Overview of Compositional Simulation. (Left) Real2Sim alignment: trajectories collected in the real world are replayed in simulation to generate paired video data for training the sim-to-real neural simulator. (Right) A DiT is used to estimate scores conditioned on different dynamics, including Control Dynamics (actions) and Visual Dynamics (simulated observations). These scores are composed during sampling to enable Dynamic Guidance methods.
Real-world deployment with Compositional Simulation. Large volumes of $(\mathcal{V}_{\text{sim}}, \mathcal{A})$ pairs are collected from the classical simulator and transformed into corresponding $(\mathcal{V}_{\text{real}}, \mathcal{A})$ pairs, referred to as Pseudo Real Data. These, together with a small amount of real-world data, are used to train policies with improved success rates and generalization.
Tasks
We evaluate Compositional Simulation on five representative dual-arm manipulation tasks spanning diverse interaction patterns: Shake Bottle, Stack Blocks Two, Move Playing-Card Away, Place Mouse Pad, and Handover Bottle. To rigorously test generalization, we further introduce two scene variants—Cluttered (with distractors) and Colored Background (altered desktop textures)—as well as out-of-distribution object substitutions (e.g., Coca-Cola, Sprite, Nongfu Spring Oriental Leaf Tea bottles; red playing cards) that never appear in the real-world training demonstrations.
Task demonstrations. Keyframes from real-world execution on Move Playing-Card Away (top) and Shake Bottle (bottom), showing both the training object (blue card / Fanta) and unseen test objects (red card / Coca-Cola), highlighting our pipeline's generalization to novel objects.
Results
We first evaluate the photorealism of Sim2Real neural simulation, then assess downstream policy performance under multiple data-mixture regimes. Our full pipeline (Ours-Full) achieves the best scores on all six video quality metrics, and policies trained with 10 Real + 200 Pseudo Real substantially outperform all baselines across every task and distribution.
Sim2Real Neural Simulation Quality
Method
PSNR ↑
SSIM ↑
CLIP Score ↑
LPIPS ↓
FID ↓
FVD ↓
Classical Sim
16.443
0.4342
0.7564
0.3629
187.40
61.048
Baseline (SD 1.5)
16.849
0.5129
0.7526
0.3494
254.59
50.369
Zero-Shot
13.093
0.5487
0.7308
0.4756
219.74
163.83
Ours-CD
8.464
0.1486
0.7216
0.8130
434.44
239.13
Ours-VD
18.153
0.5916
0.7884
0.2813
153.12
22.311
Ours-Full
19.577
0.6484
0.8102
0.2647
147.90
15.765
Visual comparison of Sim2Real generation. Across four representative tasks, conventional diffusion baselines suffer from hallucinations, while our full pipeline faithfully reproduces scene semantics (viewpoint, object instances, background) and action dynamics (gripper timing, arm motion), yielding photorealistic results that remain action-consistent with the simulated source.
Spatial generalization on Move Playing-Card Away. Top two rows: in-domain initial positions. Middle two rows: out-of-domain positions. Bottom four rows: colored backgrounds with varying clutter. Policies trained with 10 Real + 200 Pseudo Real (ours) handle all regimes robustly, while policies trained only on real data fail to generalize beyond the demonstration region.
Videos
We present real-world execution demos and Sim2Real neural simulation comparisons. In the comparison videos, simulated inputs and pseudo-real outputs are shown side by side, demonstrating how our neural simulator transforms classical simulation into photorealistic data while preserving action consistency.
Place Mouse Pad — Simulated (left) | Pseudo-Real (middle) | Real (right)
Generalization
Compositional Simulation preserves real-world spatial statistics and object semantics, enabling Diffusion Policy to generalize well to unseen spatial layouts and object categories. Under new-object substitutions (Coca-Cola, Sprite, Nongfu Spring Oriental Leaf Tea, red playing cards), classical simulation brings essentially no improvement, whereas our Pseudo-Real data yields a substantial boost in success rate.
New-Object Generalization
Task
10 Real
20 Real
200 Sim Pre + 10 Real
10 Real + 200 Sim
10 Real + 200 PR
200 PR (0-shot)
Shake Bottle
0/30
0/30
0/30
0/30
15/30
9/30
Move Playing-Card Away
1/30
2/30
1/30
0/30
21/30
11/30
New-object generalization on Shake Bottle. Top: policy trained with 20 Real (Fanta only). Bottom: policy trained with 10 Real + 200 Pseudo Real, which successfully handles Coca-Cola, Sprite, and Nongfu Spring Oriental Leaf Tea bottles despite never seeing them in the real demonstration set.
More Visualizations
We present additional qualitative comparisons spanning Real2Sim alignment quality and Sim2Real neural simulation, further confirming that our framework preserves action semantics while faithfully reproducing real-world appearance across diverse manipulation tasks.
Extended Sim2Real neural simulation results. Visual comparisons across Adjust Bottle, Moving Playing-Card Away, Stack Blocks Three, and Ranking Blocks RGB demonstrate consistent temporal coherence and perceptual realism throughout generated sequences.
Real2Sim alignment on Move Playing-Card Away. From top to bottom: Nongfu Spring Oriental Leaf Tea, Coca-Cola, Sprite, and Fanta. Sub-millimetre geometric agreement and pixel-level texture consistency are achieved via a rule-based digital-twin alignment pipeline.
Real2Sim alignment on additional tasks. From top to bottom: Ranking Blocks RGB, Stack Blocks Three, and Stack Blocks Two.
Citation
If you find this project useful, welcome to cite us.
@article{qin2026comsim,
title={Building Scalable Real-World Robot Data Generation via Compositional Simulation},
author={Yiran Qin and Jiahua Ma and Li Kang and Wenzhan Li and Yihang Jiao and Xin Wen and Xiufeng Song and Heng Zhou and Jiwen Yu and Zhenfei Yin and Xihui Liu and Philip Torr and Yilun Du and Ruimao Zhang},
journal={arXiv preprint arXiv:2504.xxxxx},
year={2026}
}